
Pre-screen MTurk workers with custom qualifications
If you do research using MTurk, you may have run into a common issue: how to recruit exclusively workers that meet certain criteria. For instance, you may want to run a study only on colorblind people, or only people who have perfect pitch, or only people who voted in their last local election. These criteria are all pretty easy to ascertain, but you don’t want to wait to ask until the main HIT itself; then you would be paying full price for data you can’t use at all. However, it’s also not fair to let people accept a HIT, ask them the critical question, and then force them to return it if they don’t meet the necessary criteria. That hurts certain worker metrics like HIT completion rate and can affect their ability to access other HITs, through no real fault of their own.
One option I’ve seen used is a 2-part HIT. First you make a short, cheap HIT in which you ask the relevant question or two, and then you reach out to the eligible workers who completed that HIT with the link to your actual survey. This is complex and can be time consuming for the requester, though, especially if the pre-screen is extremely short.
It turns out that there is a very straightforward way to deal with this if you’re willing to use the MTurk web API. You can create custom qualifications that workers can request, either directly or by completing a test, and then assign those qualifications as a requirement for your HITs.
You can get pretty sophisticated with handling these qualifications, and there is a lot more detail on the AWS documentation pages.
Here, I’m going to demonstrate how to make a qualification test that auto-scores itself using the boto3 library for Python. It’s a simple, 2-question colorblindness test (you can view it on the worker sandbox here; sign-in required) that first asks people to self-report any known issues with their color vision, and then has them respond to an Ishihara plate. Here’s what it looks like to a worker:
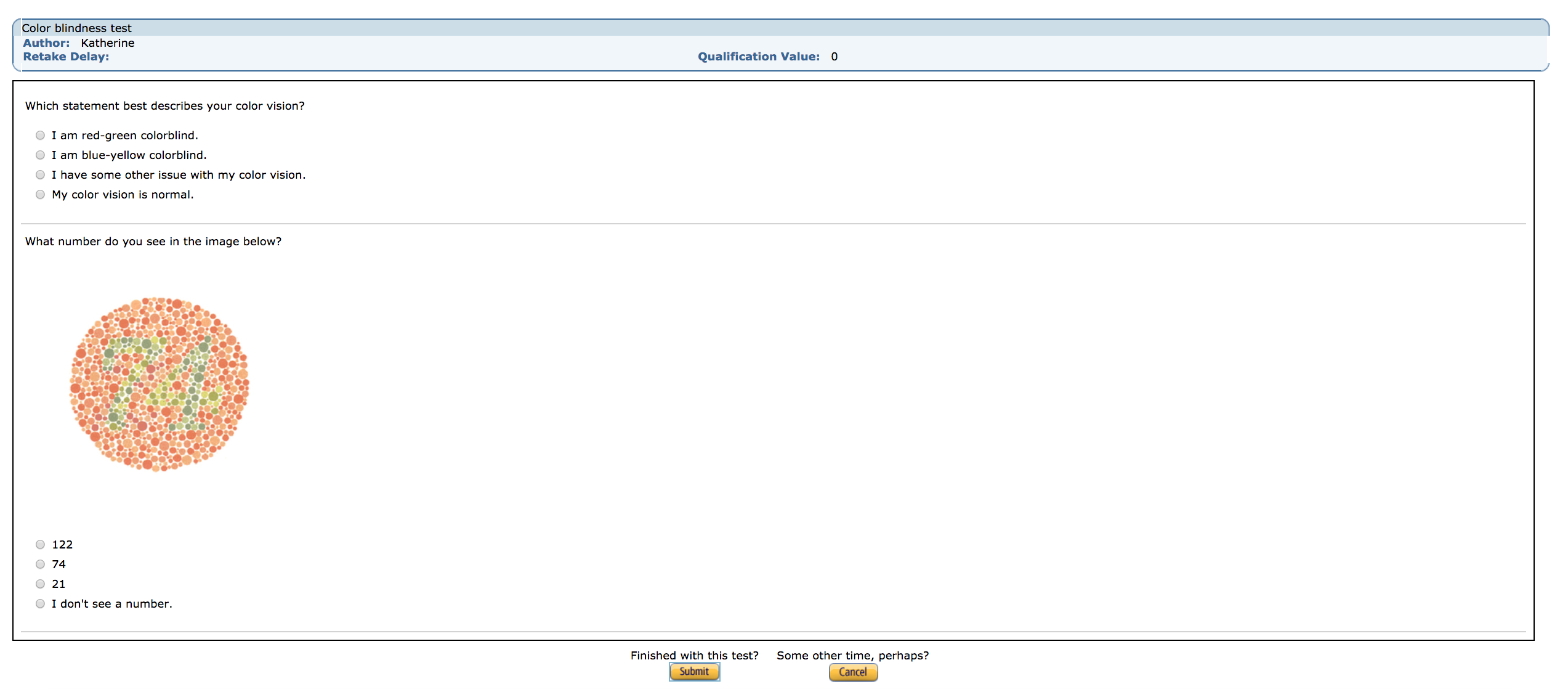
A screenshot from a live qualification test.
With this test, instead of asking about colorblindness during the HIT itself and having to throw data out after the fact, I can restrict participation to people who pass this short test.
1. Setup
To use the MTurk API, a couple of things are neccessary.
- an AWS account
- an MTurk requester account
- an MTurk sandbox requester account
- an MTurk sandbox worker account
- the boto3 library for Python, most easily installed via pip
You’ll also need to link your AWS account to both your real Requester account and to your Sandbox Requester account, and have your access credentials formatted in a way that boto3 can access them.
For more detail on how to handle setting all of this up, or to see how all the pieces fit together, you can check out this post for an in-depth guide.
With that in place, we can move on to actually creating the qualification!
2. The qualification skeleton
Making a qualification itself involves just one function call.
First, we make our client object:
import boto3
mturk = boto3.client('mturk',
region_name='us-east-1',
endpoint_url='https://mturk-requester-sandbox.us-east-1.amazonaws.com')Then, to make a qualification, we call create_qualification_type():
qual_response = mturk.create_qualification_type(
Name='Color blindness test',
Keywords='test, qualification, sample, colorblindness, boto',
Description='This is a brief colorblindness test',
QualificationTypeStatus='Active',
Test=questions,
AnswerKey=answers,
TestDurationInSeconds=300)No matter what kind of qualification you’re creating, you’ll need to give it a Name and a Description that workers will see, plus some Keywords that will help people search for it. We’re going to go ahead and set this qualification to Active with the QualificationTypeStatus argument, meaning that it will go live immediately (as live as something can go in the sandbox, that is).
The next handful of arguments are particular to the qualification type this is–in particular, a qualification type that requires a test. The Test argument needs to be a QuestionForm datatype (more on that in a second). This will specify the actual questions that make up the test. If this is left blank, a worker can request the qualification without taking a test first.
Similarly, the AnswerKey argument must be an AnswerKey data structure. This is like an auto-grader for the test. In this file (more details below), we specify how each answer to each question is scored, and what the scoring scheme is overall (a straight sum, a percent, a range, etc). A person will take the test, and if an answer key is provided, be automatically scored. We can then require that people have a certain score on the qualification test to be able to take your HIT. If no answer key is given, you’ll have to go through the tests manually (and free response answers can’t be auto-graded).
Because we have a qualification test, we have to specify how long people have to take it in seconds with the TestDurationInSeconds argument. Because this is a short little questionnare, we’ll allot 5 minutes.
3. The question file
Questions have to be passed in a very specific format. They should be .xml files, and they have a specific structure. There’s lots of detail here, and you can get pretty sophisticated in terms of your questions.
In our case, we have just two questions: a text-only question, and a question in which we present an image.
The XML file needs to start this way:
<QuestionForm xmlns='http://mechanicalturk.amazonaws.com/AWSMechanicalTurkDataSchemas/2005-10-01/QuestionForm.xsd'>
...
</QuestionForm>This URL is important for technical reasons (it identifies the location of an important file for presenting the questions).
Inside the QuestionForm tags are sections for each question. You can give it a name and an identifier (important for matching up the answer key):
<Question>
<QuestionIdentifier>self_report</QuestionIdentifier>
<DisplayName>Q1</DisplayName>
<IsRequired>true</IsRequired>
...
</Question> And then we get to the actual question content. This first question is only text:
<QuestionContent>
<Text> Which statement best describes your color vision? </Text>
</QuestionContent>But we can also present images, videos, and so on. Here’s how we’ll present the Ishihara plate:
<QuestionContent>
<Text> What number do you see in the image below? </Text>
<Binary>
<MimeType>
<Type>image</Type>
<SubType>jpg</SubType>
</MimeType>
<DataURL>https://www.spservices.co.uk/images/products/pics/1401209116aw2271.jpg</DataURL>
<AltText>Ishihara Color Plate</AltText>
</Binary>
</QuestionContent>Specifying the MimeType within the Binary tags is what allows us to embed other media.
After every QuestionContent section, you have an AnswerSpecification section. Since we just have radio button responses, we have a SelectionAnswer section, and then for each answer we have a Selection with text the worker sees, and then a secret label for that answer that only we see (and that the answer key will use to grade the worker). Like so:
<AnswerSpecification>
<SelectionAnswer>
<StyleSuggestion>radiobutton</StyleSuggestion>
<Selections>
<Selection>
<SelectionIdentifier>rg</SelectionIdentifier>
<Text>I am red-green colorblind.</Text>
</Selection>
<Selection>
<SelectionIdentifier>by</SelectionIdentifier>
<Text>I am blue-yellow colorblind.</Text>
</Selection>
<Selection>
<SelectionIdentifier>other</SelectionIdentifier>
<Text>I have some other issue with my color vision.</Text>
</Selection>
<Selection>
<SelectionIdentifier>norm</SelectionIdentifier>
<Text>My color vision is normal.</Text>
</Selection>
</Selections>
</SelectionAnswer>
</AnswerSpecification>This gets defined for each question.
Here’s what that entire file, all put together, looks like:
<QuestionForm xmlns='http://mechanicalturk.amazonaws.com/AWSMechanicalTurkDataSchemas/2005-10-01/QuestionForm.xsd'>
<Question>
<QuestionIdentifier>self_report</QuestionIdentifier>
<DisplayName>Q1</DisplayName>
<IsRequired>true</IsRequired>
<QuestionContent>
<Text> Which statement best describes your color vision? </Text>
</QuestionContent>
<AnswerSpecification>
<SelectionAnswer>
<StyleSuggestion>radiobutton</StyleSuggestion>
<Selections>
<Selection>
<SelectionIdentifier>rg</SelectionIdentifier>
<Text>I am red-green colorblind.</Text>
</Selection>
<Selection>
<SelectionIdentifier>by</SelectionIdentifier>
<Text>I am blue-yellow colorblind.</Text>
</Selection>
<Selection>
<SelectionIdentifier>other</SelectionIdentifier>
<Text>I have some other issue with my color vision.</Text>
</Selection>
<Selection>
<SelectionIdentifier>norm</SelectionIdentifier>
<Text>My color vision is normal.</Text>
</Selection>
</Selections>
</SelectionAnswer>
</AnswerSpecification>
</Question>
<Question>
<QuestionIdentifier>ishihara_39</QuestionIdentifier>
<DisplayName>Q2</DisplayName>
<IsRequired>true</IsRequired>
<QuestionContent>
<Text> What number do you see in the image below? </Text>
<Binary>
<MimeType>
<Type>image</Type>
<SubType>jpg</SubType>
</MimeType>
<DataURL>https://www.spservices.co.uk/images/products/pics/1401209116aw2271.jpg</DataURL>
<AltText>Ishihara Color Plate</AltText>
</Binary>
</QuestionContent>
<AnswerSpecification>
<SelectionAnswer>
<StyleSuggestion>radiobutton</StyleSuggestion>
<Selections>
<Selection>
<SelectionIdentifier>122</SelectionIdentifier>
<Text>122</Text>
</Selection>
<Selection>
<SelectionIdentifier>74</SelectionIdentifier>
<Text>74</Text>
</Selection>
<Selection>
<SelectionIdentifier>21</SelectionIdentifier>
<Text>21</Text>
</Selection>
<Selection>
<SelectionIdentifier>none</SelectionIdentifier>
<Text>I don't see a number.</Text>
</Selection>
</Selections>
</SelectionAnswer>
</AnswerSpecification>
</Question>
</QuestionForm>4. The answer key
The answer key looks much the same as the question form. Starts in a similar way:
<AnswerKey xmlns="http://mechanicalturk.amazonaws.com/AWSMechanicalTurkDataSchemas/2005-10-01/AnswerKey.xsd">
...
</AnswerKey>It also has a Question section for each question you asked on the test. Within that, you list out the score you want associated with each answer given on the test. For example, for the first question, we want to assign a point only to the answer “my color vision is normal.”
<Question>
<QuestionIdentifier>self_report</QuestionIdentifier>
<AnswerOption>
<SelectionIdentifier>rg</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>by</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>other</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>norm</SelectionIdentifier>
<AnswerScore>1</AnswerScore>
</AnswerOption>
</Question>Answer values can be anything you like, according to any scoring scheme. They can also be negative!
After you’re done listing out all of the questions, you need to tell MTurk how to calculate the final score with a QualificationValueMapping section. There is a lot more detail here. We’re not going to do anything fancy: just a percentage conversion. We specify a PercentageMapping and give it the max score to calculate relative to, like so:
<QualificationValueMapping>
<PercentageMapping>
<MaximumSummedScore>2</MaximumSummedScore>
</PercentageMapping>
</QualificationValueMapping>And here’s what the entire file looks like, strung together:
<AnswerKey xmlns="http://mechanicalturk.amazonaws.com/AWSMechanicalTurkDataSchemas/2005-10-01/AnswerKey.xsd">
<Question>
<QuestionIdentifier>self_report</QuestionIdentifier>
<AnswerOption>
<SelectionIdentifier>rg</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>by</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>other</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>norm</SelectionIdentifier>
<AnswerScore>1</AnswerScore>
</AnswerOption>
</Question>
<Question>
<QuestionIdentifier>ishihara_39</QuestionIdentifier>
<AnswerOption>
<SelectionIdentifier>122</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>21</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>none</SelectionIdentifier>
<AnswerScore>0</AnswerScore>
</AnswerOption>
<AnswerOption>
<SelectionIdentifier>74</SelectionIdentifier>
<AnswerScore>1</AnswerScore>
</AnswerOption>
</Question>
<QualificationValueMapping>
<PercentageMapping>
<MaximumSummedScore>2</MaximumSummedScore>
</PercentageMapping>
</QualificationValueMapping>
</AnswerKey>Now that we have these two files, we load them in. We can do this by adding two lines like this at the top of the script that actually makes the qualification:
questions = open(name='color_qs.xml', mode='r').read()
answers = open(name='color_ans_key.xml', mode='r').read()This reads these files in and assigns their contents to these variables. We then pass these variables into our create_qualification_type function call as arguments to Test and AnswerKey.
5. Using qualifications in a HIT
So here’s the entire script. Once this script is run, the qualification exists permanently in an active state (unless it’s deleted).
import boto3
questions = open(name='color_qs.xml', mode='r').read()
answers = open(name='color_ans_key.xml', mode='r').read()
mturk = boto3.client('mturk',
region_name='us-east-1',
endpoint_url='https://mturk-requester-sandbox.us-east-1.amazonaws.com')
qual_response = mturk.create_qualification_type(
Name='Color blindness test',
Keywords='test, qualification, sample, colorblindness, boto',
Description='This is a brief colorblindness test',
QualificationTypeStatus='Active',
Test=questions,
AnswerKey=answers,
TestDurationInSeconds=300)
print(qual_response['QualificationType']['QualificationTypeId'])It’s important to make a note of the qualification’s unique ID, which is why I print it upon creation (you can also look it up on the MTurk website itself in the URL of the qualification), as this is how we’ll refer to it when we create a HIT that requires this qualification.
Here’s what that looks like:
hit = client.create_hit(
Reward='0.01',
LifetimeInSeconds=3600,
AssignmentDurationInSeconds=600,
MaxAssignments=9,
Title='A HIT with a qualification test',
Description='A test HIT that requires a certain score from a qualification test to accept.',
Keywords='boto, qualification, test',
AutoApprovalDelayInSeconds=0,
QualificationRequirements=[{'QualificationTypeId':'3CFGE88WF7UDUETM7YP3RSRD73VS4F',
'Comparator': 'EqualTo',
'IntegerValues':[100]}]
)Looking at the QualificationRequirements argument in particular, we can see how this is structured. You pass a list of dictionaries as an argument, with each qualification getting its own dictionary. You can have lots (a location requirement, a minimum HIT approval rating, a minimum number of completed HITs, and so on), but in this case we just have the one. The dictionary has three entries: the qualification type ID, a comparator, and then an integer. These last two tell MTurk how to examine the score to determine if someone is qualified. In our case, we only want to accept workers who had a score exactly equal to 100% (meaning that they did not self-report any vision problems and answered the Ishihara plate correctly), but you could also ask for a score GreaterThan some minimum value, for example.
These custom qualifications work really well if they can be automatically scored, and if it’s only a question or two long. It’s not fair to require a long, unpaid test to complete your HIT, unless passing the test would grant them access to multiple, well-paying HITs. For most purposes, a very brief prescreen is all you’ll need.
This simplifies the process on both sides–workers can quickly get qualified (or not, in which case they can filter those HITs from their options, uncluttering their feeds), and from the requester side, this process is completely automatic. You’ll exclude less data, and won’t have to bother dealing with two separate HITs, invited-only hits, or “bonuses” that are actually payment for the real HIT you want data for.